Delve Deeper Into Level Overflow Incidents

Tank level overflow incidents are one of the most common scenarios for a loss of primary containment at a process plant. Effective alarms, as a first layer of protection, are critical to preventing tank overflows. Often the initial question after an incident is: “Did the operator get an alarm?” Immediately the focus goes to “human error” as the likely cause (the “what”). This article instead will explore the sources of human error related to alarming — with a goal of exposing the “why” and the “how” (to do it better). It provides guidance on investigating an alarm incident, including relevant questions and a “Why Tree” for determining root cause. It also offers recommendations for how to prevent or minimize human error by the operator.
First, though, it’s important to understand that human error is common and costly. Medical errors in hospitals and clinics result in approximately 100,000 deaths each year in the United States and cost the healthcare industry between $4 and $20 billion annually. In the petrochemical industries, operational error can cost upward of $80 million per incident. “Operator error” is a significant causal factor in 60–85% of industrial accidents.
What Is Human Error?
Let’s start by emphasizing that very rarely is the “human” in “human error” the true source of the problem. The explosion in data generation — some suggest that more data have been created in the last two years than in the entire previous history of the human race — certainly shows in the amount of data presented to the operator in a modern chemical plant. Increasing levels of automation (and system complexity) don’t eliminate human error, they increase the likelihood of errors.
Human error is a function of people, technology and context. Actions only can be judged as erroneous with the benefit of hindsight and when there’s an expected behavior or performance benchmark for comparison. The root cause of human error often is a design focused on technology instead of optimizing human performance; consequently, “design-induced error” probably is a more accurate description. Technology should be organized around the way users process information and make decisions.
Technology also should reinforce the user’s mental model, which captures the understanding of how a system operates and behaves. Mental models guide the operator on what information to expect and what information to look for (e.g., if vessel temperature is increasing, so should pressure). The richer and more complete the mental model is, the greater the chance of successful response to an alarm.
Types Of Human Error
To address human error, we must understand the different kinds of error and the cause of each. Errors can stem from issues with diagnosis, planning, accessing memory or with executing an action. Types of error include slips, lapses, mistakes and violations (Figure 1). Some types of errors occur more commonly with novice operators while others afflict experienced operators more. Consequently, remediation actions differ depending upon the type of error.
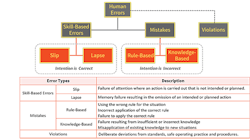
Figure 1. Errors fall into several categories, each with distinct characteristics.
Slips and lapses, also known as skill-based errors, are failures when the person had the correct intention but performed an incorrect action because of lack of the appropriate level of attention. An example of a slip is inadvertently changing a control valve output to 5.0% instead of 50.0%. Slips may result from confusing links or displays of information in the human-machine interface (HMI) or not error-checking inputs. Slips are common for expert operators who are performing a task without paying close attention; they may be multi-tasking.
A lapse (memory failure) occurs between the formulation of an intention and the execution of an associated action. An example is when a maintenance technician fails to tighten a screw after completing a procedure. The use of checklists or explicit reminders helps prevent lapses; this is why experienced pilots still use a checklist for walking down an airplane before takeoff. Additional training typically won’t correct slips or lapses.
A mistake (intention failure) occurs when the person initiates the wrong plan of action for the task at hand. Mistakes, which typically involve a problem-solving activity (like the operator responding to an alarm), fall into two categories: rule-based errors and knowledge-based ones. Rule-based errors can arise through misapplication of a good rule or use of a bad one. An example is when the operator misinterprets a valve command status as position feedback, thinking the valve is closed when it’s not.
Knowledge-based errors, which include failures of understanding (errant mental models) and perceptual errors, typically arise due to a lack of experience and because the person doesn’t have all the knowledge required to perform the task at hand. Most mistakes reflect a lack of knowledge, so training and better displays can help address them. Mistakes are common for the novice operator.
A violation (non-compliant action) is when the person intentionally does something inappropriate. It doesn’t always indicate a malicious act or devious employee. Instead, it could exemplify the “law of least effort” in action, which says that if a task appears overly difficult, the operator over time will find an easier way to do it. Scenarios where production is emphasized over safety (the operator isn’t “authorized to shut down production for safety”) also can foster violations.
Analysis of human error may take place during an incident investigation when evaluating the operator’s role. It should focus not on identifying what the person did wrong but instead on understanding why acting that way seemed to make sense. Identification of the type of human error can improve the quality and effectiveness of recommendations.
Incident Investigation
The investigation team typically gathers the information to analyze. For incidents involving operator response to alarm, the team should collect some often-overlooked information, such as:
• the history of alarms and operator actions preceding and during the incident;
• the annunciation frequency of relevant alarms, i.e., how often the operator gets the alarm;
• the shelving frequency of the relevant alarms, i.e., how often the operator uses a function to hide the alarm annunciation;
• the history of setpoint changes to the relevant alarms;
• the history of out-of-service suppression of the relevant alarms, i.e., how often an administrative process is used to hide the alarm annunciation;
• the rationalization information for the relevant alarms, including probable cause and corrective actions;
• training materials related to the relevant alarms; and
• the alarm system performance metrics, particularly the average alarm rate per operator position and the percent time in alarm flood for the operator position.
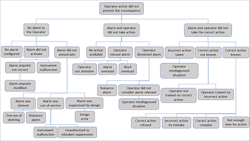
Figure 2. This includes branches for three groups of causes, with two particularly relevant to human error.
Analysis of this information helps identify the factors that contributed to the operator not taking the action to prevent the consequence. Identification of the incident root cause is important so the recommendations address the cause. It’s not uncommon for investigations to stop at the operator did not take action to prevent the consequence and blame the operator. Often, it takes more questions to get to the real causes — including understanding the operator’s thought process.
A Why Tree can generate possible causes for the incident or failure of protections and, once the cause is determined, to develop recommendations. Figure 2 shows an example Why Tree.
The Why Tree is divided into three groups of causes at the second level:
1. Why did the operator not get an alarm notification about the situation?
2. Why did the operator not take action in response to the alarm?
3. Why did the operator not take the correct action in response to the alarm?
(The first group of causes doesn’t relate as much to operator error but we’ve included it for completeness.)
Figure 3 shows the feedback model with the usual steps in alarm response. A disturbance causes a deviation or abnormal condition indication or alarm that the operator detects. The operator diagnoses the situation and then takes action in response to the alarm.
The causes at the top of the Why Tree address issues in the alarm indication, detection and diagnosis, and response.
The investigation team can work through the Why Tree using the information listed above to identify the likely causes behind the failure of the response to the alarm. Frequently, causes include instrument malfunction, operator training, and misdiagnosis of the situation related to the operator’s mental model. The data should guide the investigation, for example:
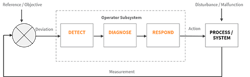
Figure 3. Detection of an issue should prompt proper diagnosis and then appropriate action by the operator.
• If no alarm was annunciated, the team should review the instrument, alarm configuration and alarm suppression history.
• If no action was taken in response to the alarm, the data can indicate if the alarm was a nuisance alarm or if the operator was overwhelmed with alarms during the event.
• The history of alarms and operator actions will answer if there was an alarm to indicate operator action was needed, if the operator took action, and if the action was correct. Multiple alarms and actions may require review.
• The team should check rationalization information to see if the correct action and probable cause were documented.
To fully process the Why Tree, the operator has to share his or her thought process at the time. This is easier to do when the investigation isn’t seen as an attempt to blame the operator but one to improve the systems. Useful recommendations only result when there’s an earnest attempt to understand the mechanisms and factors that shape the operator’s decision-making and behavior.
Analysis Of Incidents
Let’s now look at three actual events that led to serious consequences.
Gasoline tank overfill. At a Buncefield, U.K. site, operators failed to prevent a tank from overfilling; this resulted in a vapor cloud explosion. Reviewing the Why Tree shows there were two instances of “no alarm to the operator.” The alarm from the tank level gauge didn’t activate because of “instrument malfunction.” The level gauge also gave the operator misleading information. The alarm for the independent high-level shutoff failed because “alarm was out-of-service” due to “mistaken suppression” as a result of maintenance.
There are other relevant human error lessons to be learned. Managing the incoming fuel transfer should have been viewed as a safety critical task, meaning if performed incorrectly, it could lead to a major accident. The investigation showed that operators didn’t have sufficient visibility or control over the pipeline to properly manage storage of incoming fuel or to address developing abnormal situations. Performing a human reliability assessment of this safety critical task would have identified this insufficiency.
Loss of treated water (utility) in winter. A Canadian process plant had a level control valve freeze closed on its treated water tank in January. When the frozen controller alarmed high (spuriously), the operator lowered the setpoint to 75% from 80%. When a redundant level indicator alarmed low a few minutes later, the operator thought it was another high alarm and reduced the setpoint to 70%. The operator took no additional action for eight hours. When the treated water pumps began to cavitate, the operator realized that no more water was available to feed the plant’s boilers. The plant lost steam in the middle of winter.
The Why Tree indicates a failure resulting from “incorrect action taken” caused by “operator misdiagnosed situation.” With redundant level indications available, the operator, before taking action, should have confirmed the validity of the level controller high alarm by looking at the other measurement. The operator made a slip by failing to provide sufficient attention to notice that the second alarm was for low level instead of high level. The system design also contributed to the diagnosis error. Only the level controller provided visual indication of an alarm on the process graphic; the redundant level transmitter didn’t. A dozen stale alarms clouded the alarm summary display, hindering the operator from recognizing the new information. The summary display presents information in a series of columns, such as time, tag, tag description and alarm condition. There was minimal difference between the high and low alarms; the distinguishing characters (“PVHI” vs. “PVLO”) only appeared at the end of a long string of characters.
Interestingly, the company’s response to the incident was to add a low-low level alarm to both instruments. Yet, the use of the Why Tree clearly indicates the problem was not “no alarm to the operator.”
Batch sent to wrong equipment. During a batch campaign, a piping modification intended to deliver product to a designated tank instead sent it to a different tank. After several days of production, the high level alarm on the second tank triggered. The next day the high-high level alarm on the second tank activated. Production continued until material overflowed the second tank. Eventually, a field operator investigated and identified the loss of containment. The release finally was contained after more than 1,000 gallons of material was spilled. In this example, the failure “operator dismissed alarm” occurred because the alarm wasn’t considered relevant. The situation was misdiagnosed because it didn’t square with the operator’s mental model (mistake).
Errors (slips) associated with performing actions on the wrong equipment are common in industry and often also include violations. A 2007 explosion at Formosa Plastics’ Illinois plant occurred when an operator turned the wrong way at the bottom of a stairwell, leading the person to mistakenly open a running reactor (after bypassing a safety interlock) instead of one that was being cleaned. The investigation showed that this type of error had taken place in the past, indicating the design wasn’t sufficient to prevent human error. (See: “Explosion at Formosa Plastics (Illinois).”)
For additional information on this topic, check out the webinar “Impact of Human Factors on Operator Response to Alarm: Lessons from Process Industry Incidents.”
Go Beyond “Operator Error”
Tank level overflow incidents continue to be a significant issue at process plants. Minimize the chances for human error by designing the system around the way that users process information and make decisions. Analyze near-misses and incidents thoroughly to get to the root cause. If “operator error” is your root cause, then chances are you haven’t investigated deeply enough. Use of a Why Tree can help identify the contributory root causes. History has shown that if you don’t get to the root cause, then remediation steps (such as putting in another alarm or forced training) won’t prevent a repeat incident.
Consider these specific recommendations to minimize the potential for human error in operator response to an alarm:
• Identify situations that can lead to human error or where human error could prompt an incident. Put mechanisms in place to prevent or mitigate them. Include error-checking and confirmation within the HMI to minimize slips.
• Beware of hindsight bias, i.e., the tendency to perceive past events as having been more predictable than they actually were, for it will impact how well the organization can learn from the event.
• Watch out for bad recommendations that would make the situation worse (see sidebar).
• Design process graphics to help reinforce the operator’s mental model of the process and to ease diagnosis of the cause of an upset.
• To develop better diagnosis skills (to prevent mistakes), implement a training program that practices recognizing cues, expectations and operator actions. Also use pre- and post-mortem discussions to facilitate knowledge transfer within the operations team.
Bad Recommendations
Often an investigation team is so focused on a particular incident — looking at a tree rather than the forest — that its recommendations are inconsistent with the alarm philosophy. The following all-too-common recommendations damage the effectiveness of the alarm system over time.
• Add a second alarm. If the operator didn’t take action when there is one alarm, add a second for the same action as a reminder. This creates redundant alarms, one of the enemies of a good alarm system. Often, the operators stop taking action at the first alarm, knowing they can take action at the second alarm.
• Re-alarm. If the operator didn’t take action soon enough, annunciate the alarm again and again and again, until the person takes action. This increases the alarm rate to the operator and can distract from more urgent alarms.
• Raise the priority. If the operator didn’t take action, increase the priority for the alarm. This makes sense if the priority wasn’t correct. However, artificially upping the alarm priority will degrade the meaning of priority over time and conflicts with the priority system set out in the alarm philosophy.
• Put flashing text on the display. If the operator didn’t take action, make this alarm visible in a special way that can’t be missed. This creates a unique human-machine interface (HMI) view of the alarm, breaking the HMI philosophy. Over time, the displays become filled with special alarm indications until nothing seems special.
NICHOLAS P. SANDS is a Dallas-based manufacturing technology fellow at DuPont. TODD STAUFFER is director of alarm management services for exida, Sellersville, Pa. Email them at [email protected] and [email protected].
REFERENCES
Rodziewicz, T. L., Houseman, B., and Hipskind, J. E., “Medical Error Reduction and Prevention,” Nat. Ctr. for Biotech. Info., Bethesda, Md. (2021), https://www.ncbi.nlm.nih.gov/books/NBK499956/.
Wickens, C. D., Gordon-Becker, S. E., Liu, Y., and Lee, J. D., “An Introduction to Human Factors Engineering, 2nd ed., Prentice-Hall, Hoboken, N.J. (2003).
Kletz, T. R., “An Engineer’s View of Human Error,” 3rd ed., Instn. of Chem. Engs., Rugby, U.K. (2008).
Endsley, M. R., and Jones, D. G., “Designing for Situation Awareness: An Approach to User-Centered Design,” 2nd ed., CRC Press, Boca Raton, Fla. (2017).
“ANSI/ISA-18.2-2016 Management of Alarm Systems,” Intl. Soc. of Automation, Research Triangle Park, N.C. (2016).