
The term “big data” conjures up thoughts of countless sensor data points, real-time manufacturing processes or predictive modeling. Process safety isn’t usually in the mix — but it should be.
Most facilities take process hazard analyses (PHAs) very seriously, devoting considerable resources and staffing to produce a comprehensive and valuable report. The PHA of a single unit can generate upwards of 2,000 scenarios and a company usually has multiple units at a site and may operate several plants; so, the amount of data available is massive — and multiplied by the requirement to conduct PHAs every five years. The result is an enormous “data lake.”
This resource certainly fits the definition and purpose of big data. However, getting full value from this information long term requires addressing some of the current limitations of the data as well as a paradigm shift in use of the data.
Let’s consider the example PHA scenario on a simple distillation column, a debutanizer, given in Figure 1. Regardless of the technology used, the final PHA data usually are organized similar to the way shown. The two most informative fields — cause and consequence — generally are free text fields with no set structure. So, too, is the listing of safeguards. However, other key fields — severity, frequency and unmitigated risk ranking — may follow a pretty structured format.
Now, let’s define “big data.” Generally, it requires volume, variety and velocity. You must have ample amounts of information in diverse formats and generated at a rapid pace. Using a tool to capture these data in a usable way helps you ensure the veracity of what the information indicates so you can drive value.
Understanding PHA As Big Data
Using that protocol, let’s examine PHA data.
Volume. On average, a PHA of a unit at a large-scale petrochemical plant will have anywhere from 1,500–2,000 scenarios. If that facility contains 30 units, it could have an estimated 45,000 PHA scenarios. Now, considering that PHAs are completed every five years, a plant with 30 years of PSM records could amass 270,000 scenarios.
Big data also involves individual data fields. Each scenario could have 15 data fields. Multiply your scenarios by the fields of data and a single petrochemical facility conservatively could have over 4 million fields of PHA data in its archives.
Variety. PHA data include scenario information (structured and unstructured), spreadsheets and PDFs as well as piping-and-instrumentation diagrams and other drawings. These various types of data also are captured in different ways.
Any free texts fields allow for variety of inputs. This lack of structure can prove to be a problem. We’ll address this issue and potential solutions later.
Velocity. This is one of the key components of big data. The capturing of pressure, temperature, flow and other process measurements on a periodic basis — as frequently as every few seconds — leads to rapid data accumulation.
The velocity of PHA information may not rival real-time sensor data, for example, but you could compare the high-velocity sensor data collected before/during/after a consequence with what the PHA team predicted.
Veracity. Making data connections enables you to check the validity of your PHA evaluation. Did the cause/consequence in the scenario end up the way predicted? Did safeguards operate as intended? Does a gap exist in risk mitigation?
Value. Having “proof positive” of your PHA scenarios allows you to do additional evaluations with confidence. In particular, consider conducting data comparisons focused on capturing and leveraging the knowledge in all PHAs for high-level decision-making.
However, including PHA information in a big data model requires addressing several limitations.
For the past 25 to 30 years, the industry has done an excellent job at facilitating PHAs. This generally results in up-to-date process safety information and a massive report that’s put on a shelf, either real or digital.

Figure 1. Risks from lack of flow in distillation column require mitigating actions.
The Need For A Paradigm Shift
Facilities most commonly rely on two PHA deliverables — the recommendations list with action plans and independent protection layer (IPL) or safeguard lists — to mitigate the risks identified.
As currently designed, a PHA is a snapshot. While that’s a start, it’s only a single point in time with few benefits.
Other than the list of safeguards or IPLs and recommendations, the PHA sits on a shelf. It represents an immense amount of time, effort and energy and the thinking of some of your brightest and most capable people but it’s barely used.
To fully leverage that information, we need a paradigm shift — we must begin thinking about PHAs as less of a snapshot and more like a gigapixel satellite image that allows you to zoom in and out at different altitudes and from a variety of vantage points. It consists of multiple layers with depth of detail.
This macro-level perspective would enable us to compare and crosscheck different PHA results both across similar processes and facilities. However, two notable barriers now prevent us from realizing this potential: lack of accessibility and lack of structure.
Lack of accessibility. Today’s PHA files aren’t easily searchable. Because there isn’t any structure to the data in the files, even electronic ones, you can't search effectively.
If you’re looking for specific failure, doing a free text search on your PHA may not return the results you hoped — you can’t “google” within your PHAs. You may not be able to search a single word because you may not be able to guarantee how the information was captured. For instance, a team may have used “debutanizer” instead of “vessel 100,” hampering getting relevant or comprehensive results.
Additionally, those data usually are stored in standalone software, and most common systems restrict access. They don’t allow just anyone to look at the information as a matter of data integrity and avoiding corruption.
Furthermore, a company may not use the same software at all its sites or may have changed software between PHA seasons. Data structures may differ.
Digging through the data — let alone aggregating and analyzing all this information — usually is a daunting task, to say the least.
Lack of structure. Today, most data reside in free text fields without structure and categorization. You can’t even run simple filters. We must change from embedding important information in free text fields to breaking it out into structured data categories. The difference is building a data structure where you capture details like process fluids, equipment involved and safeguard type.
Lack of accessibility and structure results in a lack of consistency. Ask yourself, “How consistent are your PHAs for the same process? For the same technology and equipment? Do they have similar causes, consequences or risk levels?”
Without an intentional structure, I would argue you can’t easily answer these questions.
Consider this: a company has two hydrofluoric acid alkylation units — one in the Middle East and one in the United States. How do the PHA evaluations for the units compare? I can confidently predict that they didn’t evaluate the same scenarios, let alone come to the same conclusions. As engineers we’d like to think teams will follow the same course of logic but it isn’t always obvious how a team arrives at its scenario consequence.
This issues also arises when examining the same technology at similar facilities. A large petrochemical owner/operator may use a single technology to produce a specific type of plastic at ten comparable facilities throughout the world. What does the risk look like for those ten plants? Can you even compare them?
Most companies currently can’t do that type of analysis — at least not cost-effectively or quickly. However, if we change the way we structure PHA data, we open up some fascinating possibilities.
Imagine being able to query: “Every time we overpressure a distillation column across our company, what’s the most frequently employed safeguard? Is it a relief device, an operator alarm or the basic process controls?” No one option likely suits all operations but the types of safeguards shouldn’t be all over the board either.
These are the types of questions you can start to answer at a corporate level to identify and address inconsistencies in your process safety departments.
The Start Of A Solution
To remove the barriers to big data, we must address the structure problems first. Let’s examine that distillation column example.
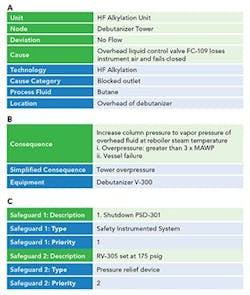
Figure 2. Adding fields (shown in blue and circled in red) to cause (a), consequence (b), and safeguards (c) provides a better structure.
Figure 2 contains all the information captured previously. It also shows suggested fields (in blue) to add for better structure. Essentially, doing so breaks out some of the information currently inside each free-text field to capture it in a more analysis-friendly way.
Let’s now look at the specific data fields to add under cause, consequence and safeguards.
Cause. Specify technology, a cause category, the process fluid and the location.
Consequence. Include a simplified consequence and the equipment involved. I suggest pulling these category fields from a master list built from the facility information. This ensures the data are linked to one master data set and will foster accurate and comprehensive filtering and analysis.
Safeguards. Stipulate safeguard type and priority level for the given scenario. Ideally, the “safeguard type” should come from a preset list specific to the company or facility. This would avoid the confusion that can arise from different descriptions of a safeguard, e.g., “RV-305,” “relief device 305” or “relief device on the debutanizer.” Such inconsistencies, while acceptable for PHA documentation, hinder filtering and analyzing the data.
Once you improve the data structure, you can run novel analytics to identify interesting patterns within the information.
Let’s consider a company that operates identical alkylation units at several sites and wants to compare evaluations done for a blocked outlet. The process fluid is butane on the overhead of the debutanizer.
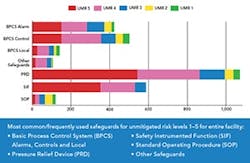
Figure 3. Comparing safeguards by unmitigated risk level can lead to significant insights.
Filtering by those parameters, the company quickly could identify matching units in the Middle East and Texas: the same technology, cost category and process fluid as well as similar equipment.
For this client, we performed a consequence analysis and found a marked variation in the consequence evaluation: the team at Plant 1 predicted a catastrophic vessel failure while the team at Plant 2 expected a gasket failure. By seeing this information side-by-side, the client could identify the discrepancy in evaluation techniques between the two PHA teams that generated vastly different severity levels.
Interestingly enough, the American Institute of Chemical Engineers’ book “Guidelines for Initiating Events and Independent Protection Layers in Layer of Protection Analysis,” https://bit.ly/35AeFvh, specifies the appropriate evaluation method (for this scenario, see Appendix E, p. 393, of the electronic version). Obviously, one team didn’t consult the guidelines.
The company didn’t realize the plants used different evaluation methodologies until it could compare similar scenarios. Without intentional data structure, this exercise invariably would have required incredible amounts of work.
Beyond consequence, we could compare how different teams mitigate similar risks. If one team includes a relief system expert, it might opt for a relief device. In contrast, the other team, if it has safety instrumented system (SIS) specialist, might specify an SIS. Now, quite honestly, we don’t lose much sleep about the choice between a relief device and an SIS from a risk-reduction perspective.
However, what if one team instead mitigated the risk for the same hazard scenario with alarms or procedures? That type of discrepancy should at least trigger a second look, not just to verify its adequacy as a safeguard but also for the cost differential of implementing and maintaining those very different types of safeguards.
Being able to compare these scenarios allows you to identify points of differentiation.
Gaining Important Insights
Looking at the data comprehensively enables you to start to compare the unmitigated and mitigated risk at different levels or between similar scenarios.
Let’s examine high-level analysis of all scenarios that result in losing feed to a specific type of column. When we filtered the consequence for “loss of feed,” we efficiently observed major differences in the unmitigated and mitigated risk rankings. While this doesn’t explain “why” you have these discrepancies, it helps you focus on where to look further.
These data also could show patterns in how you mitigate your risk. Figure 3 groups all scenario unmitigated risks by safeguard type (one of the categories we added to our data). Red indicates any scenario or group of scenarios with the highest unmitigated risk (level five). We clearly see that pressure relief devices are most frequently used to mitigate these riskiest scenarios.
When you start to analyze all these data together, you’ve got to remember that snapshot (micro) versus satellite picture (macro).
Consider an entire facility: “What does the Texas plant rely on most often for an unmitigated risk of five? Does it use relief devices? What does the Middle East plant use?”

Figure 4. Looking at the quantity of scenarios and their risks gives an indication of the overall situation at the site.
By zooming in and out of your PHA data — because the data now are structured in a way that allows you to do that — the analytics begin to get interesting.
If I just look at that example Texas plant (Figure 4), you can view the quantity of scenarios that started in each of the different areas of our risk matrix for the entire facility (not just a single PHA). There are 142 highest risk scenarios. You could average all these to come up with the unmitigated risk value at the facility level. In this example, the weighted average of the scenarios gives us an unmitigated risk value of 3.4.
You could do the same by looking at the mitigated risk value, which reflects the risk with your safeguards applied. The difference between the two essentially is your risk reduction.
Now that you can view your data in a macro-level way, you can look at one specific plant and ask, “What’s our average on unmitigated risk?” Here, it’s 3.4. “What is the mitigated risk value?” It’s 1.9 for the site. In this case, we are reducing our risk on average on most scenarios by 1.5 levels.
Now, let’s take things one step further and examine those average risk metrics a few different ways.
When we look at the aggregate data for the entire company, we have a 2.7 unmitigated risk and a 1.7 mitigated risk (Figure 5). So, the corporation has achieved a risk reduction value of 1.0.

Figure 5. Comparing the overall corporate situation to that of individual plants can spur some important questions.
Let’s zoom in on two separate facilities. Plant 1 has a risk reduction value of 0.6 while Plant 2 has one of 1.5. If these are for the same technologies with similar throughput, does that sound right? (Hint: It probably isn’t right.)
So, you should pose some questions. Start with an “I wonder…” statement: “I wonder if I have any alarms for more than one scenario. How many times do I use this specific alarm? Do we mitigate the highest risk scenarios with alarms? Do we want to mitigate them with alarms?”
You can ask those questions today — but, unless you have better data structures, you can’t answer them.
Another starting point is to key in on critical scenarios, most often high-risk ones. Then, you can ask: “Based on the risk levels of these given scenarios, are we allocating our resources appropriately? Should we budget the same resources (time, effort, energy and capital) to alarms as we do relief system design? What should our operator training focus on? Is our mechanical integrity program and inspection schedule prioritized to our more critical safeguards?”
Unless you can pull, filter and analyze your data comprehensively, you may be misallocating or wasting money.
Realizing The Potential Of PHA Data
In the end, we as an industry need a paradigm shift to embrace big data concepts within PHA data. We no longer can view PHA data as that “snapshot in time.” Instead, we must consider how to organize and structure PHA data better so we can realize the potential of those macro-level analyses.
We must start comparing data between similar processes, sites and failures so that we can discover what these data tell us about how we are mitigating risk in our facilities.
Big data tools can help move us forward but they can’t think for us. We must begin to think differently about the value our PHA data can bring to our risk mitigation strategies.
PATRICK NONHOF is managing director of Provenance Consulting, a Trinity Consultants Co., Borger, Texas. HEATHER FEIMSTER is Corpus Christi, Texas-based marketing communications specialist for Trinity Consultants. Email them at [email protected] and [email protected].